模型评估
我们就在这篇文章来说一下,模型的一些评估指标.以便更好地理解模型的性能。
准确率(Accuracy)
准确率是最常用的评估指标之一,表示模型预测正确的样本占总样本的比例。公式如下:
$$ \text{Accuracy} = \frac{\text{TP} + \text{TN}}{\text{TP} + \text{TN} + \text{FP} + \text{FN}} $$其中:
- TP(True Positive):真正例,模型正确预测为正类的样本数
- TN(True Negative):真负例,模型正确预测为负类的样本数
- FP(False Positive):假正例,模型错误预测为正类的样本数
- FN(False Negative):假负例,模型错误预测为负类的样本数
也就是其实就是这个模型对于所有样本的预测正确率。但是如果它这个样本不平衡的话,也就是正样本和负样本的比例不平衡的话,这个准确率就不是一个很好的指标了。就是比如说在一个数据集中,95%的样本是负类,5%的样本是正类。也就是它只要把样本全部预测成负类也有95%的准确率,这样就会导致模型的评估不准确。
精确率(Precision)
精确率是指在所有被预测为正类的样本中,实际为正类的比例。公式如下:
$$\text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}}$$精确率反映了模型在正类预测中的准确性。高精确率意味着模型在预测正类时较少出现误报。
通过这指标我们就可以看到我们的模型在预测正类时的准确性.
召回率(Recall)
召回率是指在所有实际为正类的样本中,模型正确预测为正类的比例。公式如下:
$$\text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}}$$召回率反映了模型对正类样本的捕捉能力。高召回率意味着模型能够识别出大部分正类样本。
通过这个指标我们就可以看到我们的模型对于正类样本的捕捉能力.
F1-score
F1-score是精确率和召回率的调和平均数,用于综合评估模型的性能。公式如下:
$$\text{F1-score} = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}}$$F1-score在精确率和召回率之间取得平衡,适用于需要同时考虑这两个指标的场景。它特别适用于正负样本不平衡的情况。 F1-score的值越高,表示模型的综合性能越好。
召回率和精确率的平衡
召回率和精确率之间通常存在一定的权衡关系。提高召回率可能会导致精确率下降,反之亦然。因此,在实际应用中,需要根据具体任务的需求来选择合适的评估指标。例如,在医疗诊断中,可能更关注召回率,以确保尽可能多地识别出患病患者;而在垃圾邮件过滤中,可能更关注精确率,以减少误报。
ROC曲线和AUC
ROC曲线(Receiver Operating Characteristic Curve)是一个用于评估二分类模型性能的图形工具。它通过绘制真正率(TPR)和假正率(FPR)来展示模型在不同阈值下的表现。AUC(Area Under the Curve)是ROC曲线下的面积,用于量化模型的整体性能。AUC的值介于0和1之间,值越大表示模型性能越好。如图

什么是ROC曲线和AUC? ROC曲线是一个二维图形,用于展示二分类模型在不同阈值下的性能。横轴表示假正率(FPR),纵轴表示真正率(TPR)。AUC是ROC曲线下的面积,表示模型的整体性能。也就是这个AUC的值越大,表示模型性能越好。
看一下几种情况,当auc=1时,如图

也就是存在一个阈值,使得模型的假正率为0,真正率为1,这种情况是理想的。
当auc=0.7时,如图
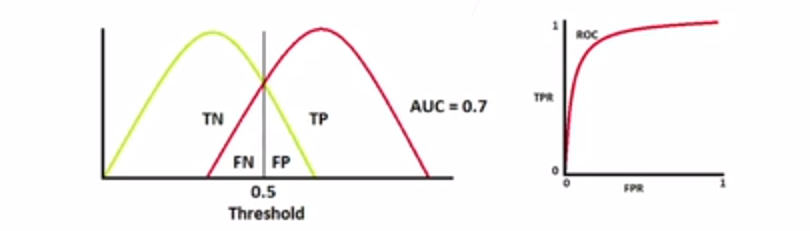
也就是,这个阈值并不可以使得模型的假正率为0,真正率为1,这种情况是比较常见的。也就是有一些假正例和假负例没有被正确分类。
当auc=0.5时,如图

也就是,这个阈值并不能使得模型的假正率为0,真正率为1,这种情况是最差的。也就是模型的预测结果和随机猜测没有区别。
还有一种就是auc=0时,如图

这个也挺好的,也是完全区分正负判例,与只不过反了而已.
混淆矩阵
混淆矩阵是一个用于可视化分类模型性能的工具,它展示了模型在不同类别上的预测结果。混淆矩阵通常是一个二维表格,其中行表示实际类别,列表示预测类别。通过混淆矩阵,我们可以直观地看到模型在各个类别上的预测情况。 混淆矩阵的形式如下:
| 实际/预测 | 正类 | 负类 |
|---|---|---|
| 正类 | TP | FN |
| 负类 | FP | TN |
混淆矩阵可以帮助我们更好地理解模型的预测结果,识别出哪些类别容易被混淆,以及模型在不同类别上的表现。
混淆矩阵的可视化
我们可以使用Python中的seaborn库来可视化混淆矩阵。以下是一个示例代码:
|
|
总结
在模型评估中,我们使用了多种指标来全面了解模型的性能,包括准确率、精确率、召回率、F1-score、ROC曲线和混淆矩阵等。这些指标各有侧重,适用于不同的场景和需求。在实际应用中,我们需要根据具体任务的特点,选择合适的评估指标,以便更好地优化和改进模型。